Schema Evolution in Data Lake Environments: Problems and Solutions
Abstract
This paper examines the critical role of schema evolution in data lake environments, addressing common problems and presenting solutions through open-source projects, focusing on Apache Iceberg. Data lakes, characterized by their vast storage capabilities and flexibility in handling diverse data types, face unique schema management challenges due to the dynamic nature of data sources.
Schema evolution, or adapting database schema over time, becomes essential in maintaining data integrity, supporting new analytic requirements, and ensuring data governance. However, schema evolution in data lakes encounters specific issues such as schema drift, metadata scalability, and performance degradation during schema changes. We explore how Apache Iceberg and other projects like Delta Lake and Hudi offer robust solutions for managing schema evolution effectively. These include transactional support, scalable metadata management, and schema versioning, which ensure data lakes can evolve without compromising data quality or system performance.
Introduction
Schema evolution refers to the iterative process of modifying a database’s schema to accommodate changes in data structure, requirements, and analytical needs without compromising data integrity or application functionality. Schema evolution poses unique challenges in the context of data lakes, which store vast amounts of structured and unstructured data. Data lakes serve as a central repository for raw data, making them inherently more flexible and susceptible to issues like schema drift, where the structure of incoming data changes unpredictably over time. Additionally, the need for scalability, data governance, and query performance further complicates schema evolution in data lakes.
The advent of open-source projects such as Apache Iceberg, Delta Lake, and Hudi has introduced new methodologies for addressing these challenges. These projects provide mechanisms for schema versioning, backward and forward compatibility, and efficient metadata management, which are crucial for maintaining the integrity and usability of data lakes.
Apache Iceberg, in particular, stands out for its innovative approach to handling schema evolution, offering solutions that mitigate common problems associated with data lakes. This paper delves into the necessity of schema evolution in data lakes, identifies the issues it aims to solve, and evaluates how Apache Iceberg and similar open-source projects contribute to resolving these issues. Through this exploration, we aim to highlight the importance of schema evolution strategies in ensuring the long-term viability and effectiveness of data lake environments.
The Necessity of Schema Evolution in Data Lakes
Data lakes have become integral to organizations seeking to capitalize on the vast amounts of data generated from various sources. These repositories accommodate a wide array of data types, from structured to unstructured, enabling comprehensive analytics and insights. However, the dynamic nature of data generation and acquisition imposes significant challenges, particularly in schema management. Schema evolution emerges as a crucial process in this context, ensuring that data lakes remain flexible, scalable, and relevant to evolving business and analytical needs.
Dynamic Data Sources and Formats
Data lakes ingest data from diverse sources, each with its unique format and structure. As businesses evolve, so do their data sources, introducing new data types or altering existing formats. Schema evolution allows data lakes to adapt to these changes seamlessly, incorporating new data types without disrupting existing analytics and applications. Without such mechanisms, data lakes risk becoming obsolete, filled with outdated or incompatible data formats that hinder analysis.
Scalability and Flexibility Requirements
The essence of a data lake lies in its ability to store petabytes of data and scale according to organizational needs. This scalability extends to schema management, where the ability to evolve schemas without extensive downtime or performance degradation is paramount. Schema evolution ensures that as data volume grows and diversifies, the underlying schema can adjust accordingly, maintaining system performance and query efficiency.
Data Governance and Quality Control
Effective data governance ensures that data within the lake remains accurate, consistent, and accessible. Schema evolution plays a pivotal role in data governance by enabling the enforcement of data quality rules and standards as data evolves. For instance, adding new constraints or fields to a schema as part of governance policies requires schema evolution capabilities. Without it, ensuring data quality and compliance with regulatory standards becomes challenging, potentially leading to data integrity issues.
Supporting New Analytical Requirements
The analytical needs of an organization are never static; they change to reflect new business objectives, market conditions, and technological advancements. Schema evolution facilitates the introduction of new data models and structures to support these emerging analytical requirements. It allows data lakes to remain relevant and valuable, providing the necessary data structures for new types of analysis and reporting.
Problems in Data Lake Schema Evolution
Schema evolution in data lakes introduces several challenges that can complicate data management and utilization. These issues primarily stem from the vast scale and diversity of data within data lakes, alongside the need for flexibility in handling this data. By exploring specific examples and scenarios, we can better understand the complexities of schema evolution within these environments.
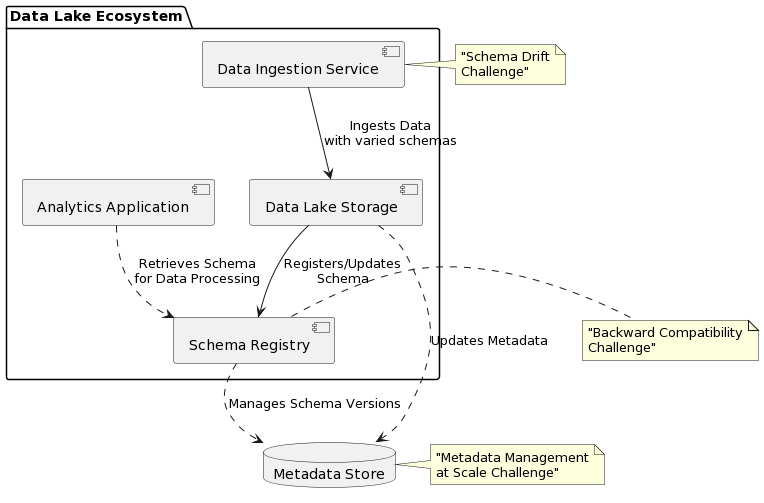
Schema Drift and Inconsistency
Example: A data lake collects event data from various sources, including web applications, IoT devices, and mobile apps. Each source periodically updates its data format - for instance, a mobile app adds a new field, deviceBatteryLevel, to its event logs. Without a coordinated schema evolution strategy, these incremental changes lead to schema drift, resulting in inconsistent data that complicates analysis and querying.
Scenario Illustration: Initially, the schema for event data might look like this:
{
"eventType": "click",
"eventTime": "2021-07-01T12:00:00Z",
"userId": "user123"
}
After the schema drift, new event data might include additional fields:
{
"eventType": "click",
"eventTime": "2021-07-01T12:00:00Z",
"userId": "user123",
"deviceBatteryLevel": 85
}
This discrepancy creates challenges in querying and aggregating data, as analysts must account for the presence or absence of new fields across different periods.
Data Versioning and Backward/Forward Compatibility
Example: A data lake undergoes a schema change to split a fullName field into firstName and lastName for more detailed user analysis. This change requires maintaining backward compatibility for applications still using the fullName field and forward compatibility for new applications expecting the split fields.
Scenario Illustration: Original schema:
{
"userId": "user123",
"fullName": "Jane Doe"
}
After schema evolution, new records follow a different format:
{
"userId": "user123",
"firstName": "Jane",
"lastName": "Doe"
}
This evolution necessitates versioning mechanisms to manage and access different data versions, complicating data retrieval and analysis.
Metadata Management at Scale
Example: The metadata describing these schemas grows exponentially as the data lake’s schema evolves to include new data sources, each with its unique schema. This growth challenges the data lake’s ability to manage and query metadata efficiently, impacting overall system performance.
Scenario Illustration: Initially, the metadata might catalog a manageable number of schemas. However, as new sources are added and existing ones evolve, the catalog expands significantly, encompassing hundreds or thousands of distinct schema versions. This expansion necessitates robust metadata management systems capable of handling the scale and complexity of the information.
Performance Implications of Schema Changes
Example: A data lake implements a schema change that requires reprocessing historical data to fit the new schema format. This resource-intensive reprocessing task leads to an increased load on the data lake’s infrastructure and potential performance degradation for other operations.
Scenario Illustration: Consider a schema change that adds a new column category to a large dataset containing billions of records. Implementing this change might involve scanning and updating each record to include the new column. This process could significantly impact query performance and data ingestion rates during the transition period.
Open-Source Projects for Schema Evolution in Data Lakes
Schema evolution within data lakes presents unique challenges, necessitating sophisticated solutions to ensure data integrity, compatibility, and performance. Open-source projects play a pivotal role in addressing these challenges, offering robust frameworks and tools designed to manage schema evolution effectively. This section explores several key open-source projects that have become instrumental in facilitating schema evolution in data lake environments. It highlights their features, capabilities, and how they contribute to solving schema evolution problems.
Apache Iceberg
Apache Iceberg [1] is a high-performance table format designed for massive analytic datasets. It provides a foundation for building complex data infrastructures, including data lakes, by offering features to improve schema evolution. Key capabilities include:
- Schema Evolution Without Downtime: Iceberg supports adding, renaming, and deleting columns without affecting ongoing queries, ensuring minimal downtime.
- Versioning and Compatibility: Iceberg maintains a snapshot of each schema version, allowing backward and forward compatibility. This feature enables data engineers to seamlessly access and query data across different versions.
- Transactional Support: Iceberg tables are atomic, ensuring that schema changes are either completely applied or not at all, which helps maintain data integrity across transactions.
Delta Lake
Delta Lake [3] is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. It addresses several schema evolution challenges, including:
- Schema Enforcement and Evolution: Delta Lake provides schema enforcement mechanisms to prevent incompatible data from corrupting the dataset. It also allows for safe schema evolution with explicit commands or by inferring changes during data ingestion.
- Scalable Metadata Handling: By maintaining a transaction log that records every change made to the data lake, Delta Lake efficiently manages metadata, even at scale, ensuring consistent data views.
- Time Travel: This feature allows users to query previous versions of the data, offering insights into schema changes over time and facilitating data auditing and rollback.
Apache Hudi
Apache Hudi [2] is an open-source data management framework that simplifies incremental data processing and pipeline development. Hudi’s approach to schema evolution includes the following:
- Schema Versioning and Evolution: Hudi supports schema changes during data ingestion, allowing fields to be added or modified as data evolves. This capability ensures datasets remain queryable and consistent, even as schemas change.
- Complex Data Structures: Hudi handles complex nested data structures, making it suitable for evolving schemas in data lakes that store semi-structured or unstructured data.
- Efficient Metadata Management: With its built-in indexing and metadata management, Hudi optimizes query performance, which is crucial for maintaining high performance in data lakes with evolving schemas.
Solutions Offered by Apache Iceberg
Apache Iceberg, an open-source table format, addresses many inherent challenges of schema evolution in data lakes. By offering a comprehensive set of features designed to manage and mitigate issues related to schema changes, Iceberg ensures that data lakes remain robust, scalable, and adaptable over time. This section outlines the key solutions provided by Apache Iceberg to facilitate efficient schema evolution.
Schema Evolution Without Downtime
Apache Iceberg allows for schema modifications such as adding new columns, renaming existing ones or deleting unnecessary columns without interrupting the data lake’s operations. This capability is critical for businesses that rely on continuous data processing and cannot afford significant downtime.
Example: To add a new column category to a table, Iceberg permits the operation without requiring a complete table rewrite, allowing existing queries to run uninterrupted.
Fine-grained Schema Versioning
Iceberg maintains a detailed history of schema versions, enabling fine-grained control over schema evolution. This versioning system allows data engineers to track changes, revert to previous schema versions if necessary, and ensure compatibility across different versions of the data.
Example: If a schema change inadvertently introduces errors, Iceberg’s versioning allows easy rollback to a previous, stable schema version, ensuring data integrity is maintained.
Transactional Support with ACID Properties
One of Iceberg’s standout features is its support for ACID transactions, which guarantees atomicity, consistency, isolation, and durability of schema changes. This support ensures that any modification to the schema is either fully applied or not at all, preventing partial updates that could lead to data inconsistency.
Example: When multiple operations are performed simultaneously, such as schema updates and data insertions, Iceberg ensures that these operations are atomic, maintaining data consistency.
Scalable Metadata Management
Iceberg’s approach to metadata management is designed to handle large-scale datasets efficiently. Iceberg significantly reduces the overhead associated with schema evolution by separating the metadata from the data itself and optimizing how metadata is stored and accessed.
Example: Iceberg stores metadata in compact, lightweight files optimized for quick access, enabling rapid schema updates and queries even in enormous datasets.
Hidden Partitioning for Performance
To enhance query performance without complicating schema design, Iceberg supports hidden partitioning. This feature allows data lakes to maintain high-performance data access patterns, irrespective of how the underlying data or schema evolves.
Example: Iceberg can partition data by date without requiring explicit fields, improving query performance while keeping the schema simple.
Time Travel and Auditability
Iceberg provides time travel capabilities, allowing users to query data as it existed. This feature is invaluable for auditing, debugging, and understanding the impact of schema changes over time.
Example: Analysts can query the state of a dataset before and after a schema change to assess its impact, providing insights into data trends and anomalies that may result from schema evolution.
Practical Implementations and Code Examples in Schema Evolution with Apache Iceberg
Apache Iceberg provides robust mechanisms for schema evolution, allowing data engineers to implement changes efficiently while ensuring data integrity and compatibility. This section demonstrates practical implementations and code examples of schema evolution tasks using Apache Iceberg, highlighting its flexibility and power in managing complex data lake environments.
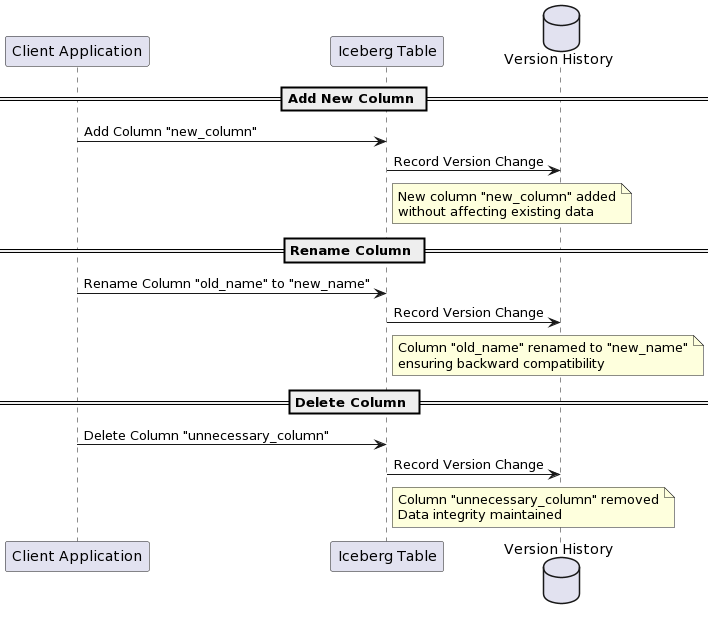
Adding a New Column
One common schema evolution task is adding a new column to an existing table. Apache Iceberg allows this operation without affecting the current data, ensuring backward compatibility.
Code Example:
import org.apache.iceberg.Schema;
import org.apache.iceberg.types.Types;
// Assuming table is an existing Iceberg table
Schema updatedSchema = new Schema(
table.schema().columns(),
Types.NestedField.optional(3, "new_column", Types.StringType.get())
);
table.updateSchema().addColumn("new_column", Types.StringType.get()).commit();
This code snippet demonstrates how to add an optional column named new_column of type String to an existing table. Iceberg’s schema evolution operations are transactional, ensuring that the schema update either fully applies or rolls back in case of failure, thus maintaining data integrity.
Renaming a Column
Renaming a column is necessary when aligning data models with evolving business terminologies or correcting previous design decisions. Iceberg supports column renaming directly without impacting the data stored.
Code Example:
// Rename column from "old_name" to "new_name"
table.updateSchema().renameColumn("old_name", "new_name").commit();
This operation changes the column name in the schema, with Iceberg handling the underlying metadata adjustments to reflect this change, ensuring that data access and queries continue to work seamlessly.
Deleting a Column
Removing obsolete or unnecessary data fields helps optimize storage and improve query performance. Iceberg safely allows column deletion, ensuring that existing data is not compromised.
Code Example:
// Delete column "unnecessary_column"
table.updateSchema().deleteColumn("unnecessary_column").commit();
Deleting a column with Iceberg updates the schema while preserving the integrity and accessibility of the remaining data. This operation is crucial for maintaining lean and relevant data models over time.
Evolution of Complex Types
Schema evolution often involves complex types, such as nested structures or arrays. Iceberg’s comprehensive type system and schema evolution capabilities support modifications within these complex structures.
Code Example:
// Add a new field to a struct within an existing column
table.updateSchema()
.addColumn("user_info.address", Types.NestedField.optional(4, "postcode", Types.StringType.get()))
.commit();
This example adds a new field postcode to a nested struct address within the column user_info. Iceberg’s support for deeply nested schema changes simplifies the management of complex data models, enabling granular evolution of data structures.
Time Travel Query
Apache Iceberg’s time travel feature allows querying data as it was at a specific time, enabling data auditing and historical analysis.
Code Example:
TableIdentifier identifier = TableIdentifier.parse("my_catalog.my_db.my_table");
Table table = CatalogUtil.loadTable(HadoopCatalogs.create(conf), identifier);
// Query data as of a specific snapshot
DataFrame historicalData = spark.read()
.format("iceberg")
.option("snapshot-id", table.snapshot(1234567890L).snapshotId())
.load("my_catalog.my_db.my_table");
By specifying a snapshot ID, users can access historical data, facilitating audits and understanding the impact of schema evolution over time.
Best Practices for Schema Evolution in Data Lakes
Effectively managing schema evolution in data lakes is crucial for maintaining data integrity, ensuring data quality, and supporting the flexible use of data assets. Given the challenges associated with schema evolution, adhering to best practices can significantly mitigate risks and enhance the agility and resilience of data lake environments. This section outlines key best practices for managing schema evolution in data lakes.
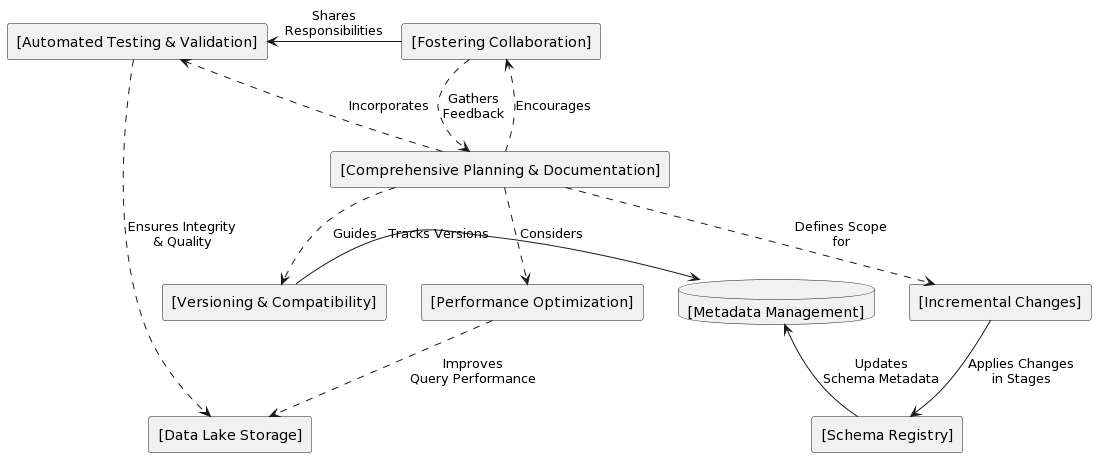
Comprehensive Planning and Documentation
Before implementing any schema changes, it is essential to plan thoroughly. This planning should include assessing the impact of changes on existing data, applications, and downstream processes. Detailed documentation of the current schema, proposed changes, and the rationale behind them helps understand the evolution process and facilitates communication among team members.
Actionable Strategy: Create a schema change management plan outlining each process step, including rollback strategies, from proposal to implementation. Document all schema versions and changes comprehensively.
Implement Incremental Changes
Applying schema changes incrementally rather than in large, infrequent updates can reduce the complexity and risk associated with each change. Smaller, more manageable changes are easier to monitor, troubleshoot, and, if necessary, roll back without significantly impacting data lake operations.
Actionable Strategy: Break down large schema updates into smaller, logical changes that can be applied sequentially. Test each incremental change thoroughly before proceeding to the next.
Employ Versioning and Compatibility Strategies
Utilizing schema versioning and ensuring backward and forward compatibility is critical for minimizing disruption to existing applications and data processes. These practices allow data lakes to accommodate new data and applications without losing the ability to process and analyze historical data.
Actionable Strategy: Adopt tools and frameworks like Apache Iceberg that support schema versioning and compatibility. Define and enforce compatibility rules for all schema changes.
Leverage Automated Testing and Validation
Automated testing frameworks can significantly enhance the reliability of schema evolution processes. Organizations can catch and address potential issues by automatically validating changes against a suite of tests before they affect production systems.
Actionable Strategy: Develop a comprehensive automated test suite covering data integrity, application functionality, and performance benchmarks. Run these tests as part of the schema change deployment process.
Optimize for Performance and Scalability
Schema changes can have significant implications for query performance and data processing scalability. Optimizing schema design and evolution processes for performance from the outset can help prevent bottlenecks and ensure efficient data lake operations.
Actionable Strategy: Consider the performance impact of schema changes, including indexing strategies and data partitioning schemes. Utilize performance testing to gauge the impact of changes and adjust strategies accordingly.
Foster Collaboration and Communication
Effective schema evolution requires close collaboration among data engineers, analysts, and business stakeholders. Regular communication ensures that all parties know proposed changes, understand their implications, and can provide feedback or raise concerns.
Actionable Strategy: Establish a cross-functional schema evolution working group to facilitate discussion and decision-making around schema changes. Use collaborative tools to share plans, updates, and feedback.
Case Studies: Schema Evolution in Data Lakes
The implementation of schema evolution strategies within data lake environments can vary widely across different industries and organizations. This section explores case studies that illustrate the challenges, solutions, and outcomes associated with schema evolution in data lakes, providing insights into best practices and lessons learned.
Case Study 1: E-commerce Platform
Challenge: An e-commerce platform experienced rapid growth, leading to the expansion of its product catalog and the introduction of new user interaction data. The schema of their data lake needed frequent updates to accommodate unique product attributes and user metrics. Implementing these changes without disrupting the ongoing analysis and data processing pipelines was the primary challenge.
Solution: The platform adopted Apache Iceberg to manage its data lake schema. Iceberg’s schema evolution capabilities allowed the company to incrementally add new columns for product attributes and user metrics. They also leveraged Iceberg’s time travel feature to maintain access to historical data, enabling trend analysis over time.
Outcome: The e-commerce platform successfully integrated new data types into their analysis without downtime or performance degradation. The ability to evolve the schema incrementally allowed for continuous improvement of product offerings and user experience insights.
Case Study 2: Financial Services Firm
Challenge: A financial services firm needed to comply with new regulatory requirements that necessitated changes to their data schema, including adding fields for transaction auditing and customer data protection. Ensuring compliance without affecting the integrity of historical data was paramount.
Solution: The firm utilized Delta Lake to enforce schema evolution while maintaining backward and forward compatibility. By implementing schema enforcement and validation rules, the firm could ensure that all data ingested met the new regulatory standards without compromising the usability of existing data.
Outcome: The financial services firm complied with the new regulations without significantly reworking their existing data pipelines. The robust schema validation and evolution features of Delta Lake minimized the risk of data corruption and ensured the firm could meet its compliance deadlines.
Case Study 3: Healthcare Research Organization
Challenge: A healthcare research organization needed to incorporate new types of clinical trial data into their data lake, which required complex schema changes, including modifications to nested structures and arrays. The organization needed to implement these changes while ensuring data integrity for ongoing research projects.
Solution: By adopting Apache Hudi, the organization evolved its schema to include new clinical trial data. Hudi’s support for complex data types and schema evolution allowed the organization to make necessary changes with minimal impact on existing datasets. Automated conflict resolution and rollback capabilities ensured data integrity throughout the process.
Outcome: The healthcare research organization successfully integrated new clinical trial data into their analysis, enhancing the breadth and depth of their research capabilities. Apache Hudi facilitated a smooth transition to the new schema, ensuring ongoing research projects were not disrupted.
Summary
Schema evolution in data lakes represents a critical facet of modern data management, enabling organizations to adapt their data infrastructure to changing business requirements, regulatory environments, and technological advancements. As illustrated through exploring open-source projects like Apache Iceberg, Delta Lake, and Apache Hudi, as well as practical implementations and case studies, effective schema evolution practices are essential for maintaining data lakes’ integrity, usability, and performance.
The challenges of schema evolution – from managing heterogeneous data and ensuring compatibility to optimizing performance and ensuring data quality – underscore the complexity of this task. However, the outlined best practices, including comprehensive planning, incremental changes, employing versioning and compatibility strategies, and leveraging automated testing, offer a roadmap for navigating these challenges effectively.
The case studies further demonstrate the applicability and benefits of these strategies across various industries, highlighting how organizations can leverage schema evolution to enhance data analysis capabilities, ensure regulatory compliance, and foster innovation. The success stories of the e-commerce platform, financial services firm, and healthcare research organization provide tangible evidence of the value that well-managed schema evolution brings to data-driven enterprises.
In conclusion, schema evolution is an indispensable component of data lake management, requiring careful consideration, strategic planning, and adopting robust tools and frameworks. By embracing the principles and practices discussed in this paper, organizations can ensure their data lakes remain flexible, scalable, and aligned with evolving business objectives. As data grows in volume, variety, and velocity, the ability to evolve data schemas efficiently will remain a cornerstone of competitive advantage and operational excellence in the data-driven landscape.