LLVM IR: Design, Evolution, and Applications
Abstract
This paper provides an in-depth analysis of LLVM Intermediate Representation (IR), a pivotal component of the LLVM compiler framework. It examines its design principles, evolution, and a broad spectrum of applications. Initially, we introduce LLVM IR’s foundational design philosophy, emphasizing its static single assignment (SSA) form, modularity, and type system, which collectively facilitate advanced optimization techniques and ensure extensibility. We trace the historical development of LLVM IR, highlighting significant milestones and updates contributing to its robustness and versatility. The core of this study delves into LLVM IR operations, detailing the instruction set and its role in representing complex programming constructs.
We further explore the optimization processes LLVM employs, utilizing IR for efficient code transformation and enhancement. Applications of LLVM IR in various domains, including just-in-time (JIT) compilation, static analysis, and domain-specific language development, underscore its flexibility and utility. Additionally, we introduce metrics for performance evaluation, examining LLVM IR’s impact on compile-time, execution speed, and memory utilization, supported by case studies and benchmarks. This comprehensive review showcases LLVM IR’s critical role in modern compiler infrastructure and considers future directions, underscoring its potential to address emerging challenges in parallel computing, security, and beyond.
Introduction
The LLVM project, standing for Low-Level Virtual Machine, represents a collection of modular and reusable compiler and toolchain technologies. Despite its name, LLVM’s scope transcends that of a traditional virtual machine, providing a rich set of libraries and tools designed to facilitate the development of compilers, linkers, and similar tools across various programming languages. Central to LLVM’s architecture is its IR, a platform-independent code form that serves as a common language for all LLVM-based compilers. This IR enables high-level optimizations across different programming languages and target architectures, making LLVM a cornerstone in modern software development.
LLVM matters for several reasons:
- Its modular design allows for adding new optimizations, languages, and target architectures. This flexibility has led to LLVM’s adoption in various applications, from commercial compilers for programming languages like C, C++, and Swift to specialized toolchains for graphics shaders and high-performance computing.
- LLVM’s IR provides a unique balance between high-level language semantics and low-level machine instructions, facilitating advanced optimization techniques that improve code performance and efficiency.
- LLVM’s open-source nature and active community have fostered a collaborative environment that encourages innovation and the rapid incorporation of cutting-edge compiler technologies.
The significance of LLVM extends beyond its technical merits. It has fundamentally changed the landscape of compiler research and development, enabling academic and industrial researchers to experiment with novel compilation techniques and optimizations more freely. Moreover, LLVM has democratized access to high-quality compiler infrastructure, allowing smaller organizations and independent developers to leverage the same powerful tools as larger corporations. This paper explores the design, evolution, and applications of LLVM IR, shedding light on its enduring impact on compiler technology and software development.
LLVM IR Design Principles
The design principles of LLVM IR reflect a careful balance between high-level abstraction and low-level efficiency, aiming to serve as a versatile and powerful tool for compiler developers. Critical aspects of these principles include:

- Static Single Assignment (SSA) Form: LLVM IR employs the SSA form, where each variable is assigned exactly once and defined before use. This characteristic simplifies the optimization and analysis phases by making data dependencies explicit, thereby enabling more aggressive and effective optimizations. SSA form reduces the complexity of many compiler algorithms, facilitating code quality and performance improvements.
- Type System and Strong Typing: LLVM IR includes a rich type system that supports first-class types, such as integers of arbitrary bit-width, floating-point numbers, structures, arrays, and function pointers. This robust typing system ensures type safety and enables precise type-based optimizations, contributing to efficient machine code generation. The type system is designed to be both expressive and minimal, allowing for accurately representing high-level language constructs while avoiding unnecessary complexity.
- Modularity and Extensibility: The modular nature of LLVM IR and its supporting infrastructure allows for easy extension and adaptation to support new programming languages, target architectures, and optimizations. LLVM’s design encourages the development of reusable components, such as passes for analysis and transformation, that can be combined in flexible ways to build custom compiler pipelines tailored to specific requirements.
- Target Independence: LLVM IR is independent of any specific hardware architecture, enabling code written in LLVM IR to be compiled to any target supported by the LLVM framework. This target independence is central to LLVM’s utility as a cross-platform compiler infrastructure, facilitating the development of applications and tools that can run on various hardware platforms without modification.
- Optimization-Friendly: The structure and features of LLVM IR are specifically designed to enable a wide range of optimizations, from basic ones like constant folding and dead code elimination to more complex analyses and transformations such as loop unrolling and interprocedural optimization. LLVM’s pass-based architecture allows for flexible scheduling of optimization passes, enabling fine-tuned control over the compilation process to achieve the best possible performance.
- End-to-End Design: While LLVM IR serves as an intermediate stage in the compilation process, the overall design of LLVM encompasses the entire compilation pipeline, from front-end parsing and IR generation to backend code generation and optimization. This end-to-end consideration ensures that LLVM IR integrates smoothly with other components of the LLVM ecosystem, supporting efficient translation of high-level language constructs to optimized machine code.
These design principles underpin the success and widespread adoption of LLVM IR in various domains, from system software and application development to specialized areas like high-performance computing and embedded systems. LLVM IR plays a pivotal role in modern software development and compiler research by providing a powerful, flexible, and efficient platform for compiler construction.
Example of an LLVM IR
Below is an example of LLVM IR code demonstrates some basic constructs, including function definition, arithmetic operations, conditional branching, and memory access. This example represents a simple function that takes two integers as arguments, computes their sum, and returns the result if it is non-negative; otherwise, it returns zero.
define i32 @add_positive(i32 %a, i32 %b) {
entry:
%sum = add i32 %a, %b ; Adds %a and %b, stores the result in %sum
%isPositive = icmp sgt i32 %sum, 0 ; Compares %sum to 0, result is true if %sum > 0
br i1 %isPositive, label %return_sum, label %return_zero
return_sum: ; Label for returning %sum
ret i32 %sum
return_zero: ; Label for returning 0
ret i32 0
}
-
Function Definition: The
definekeyword starts the definition of a function namedadd_positivethat returns a 32-bit integer (i32) and takes two 32-bit integer parameters (i32 %a, i32 %b). The function name is@add_positive. -
Labels: The
entry:,return_sum:, andreturn_zero:are labels marking positions in the function. Labels identify blocks of instructions, facilitating control flow within the function. -
Arithmetic Operation: The
%sum = add i32 %a, %binstruction performs an addition of%aand%b. The result is a 32-bit integer stored in%sum. -
Comparison Operation: The
%isPositive = icmp sgt i32 %sum, 0instruction compares%sumto0using a signed greater-than comparison (sgt). The result is a 1-bit integer (boolean) stored in%isPositive, indicating whether%sumis greater than0. -
Conditional Branch: The
br i1 %isPositive, label %return_sum, label %return_zeroinstruction branches to thereturn_sumlabel if%isPositiveis true (non-zero) and to thereturn_zerolabel if%isPositiveis false (zero). -
Return: The
ret i32 %suminstruction returns the value of%sumfrom the function if thereturn_sumlabel is reached. Theret i32 0instruction returns0from the function if it reachesreturn_zerolabel. -
Comments: A semicolon (
;) precedes comments in LLVM IR. In this example, comments explain the purpose of each instruction or label.
This simple LLVM IR example showcases the basic syntax and structure of LLVM IR code, illustrating function definitions, basic arithmetic, and logical operations, and conditional branching for control flow of execution based on computed values.
Evolution of LLVM IR
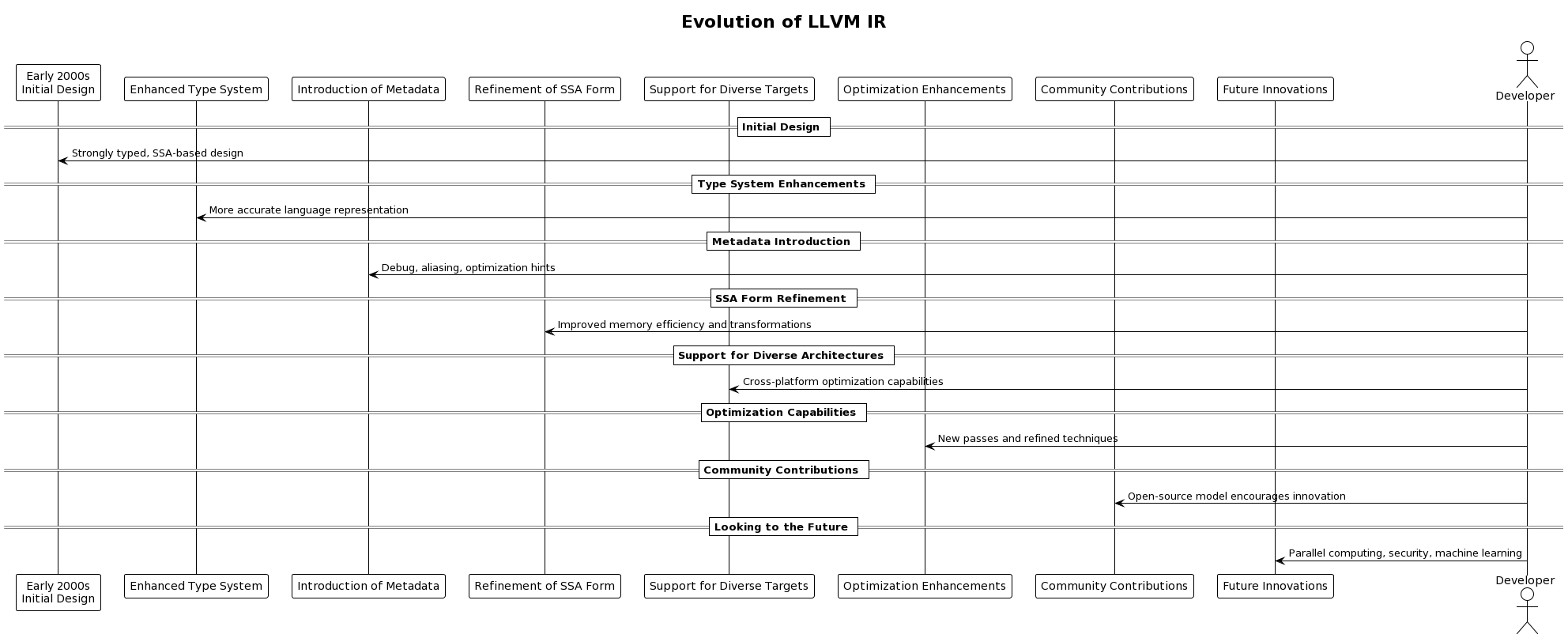
The evolution of LLVM IR is a testament to the dynamic and collaborative nature of compiler technology development. Since its inception, LLVM IR has undergone significant transformations driven by the need to address evolving computational challenges, optimize performance across diverse hardware architectures, and support an expanding range of programming languages and paradigms.
The genesis of LLVM IR can be traced back to the early 2000s, with the LLVM project initially aiming to provide a modern, high-quality compilation framework. The design of LLVM IR was revolutionary, introducing a strongly typed, easily analyzable, and modifiable intermediate form that was both human-readable and machine-friendly. This design set the stage for LLVM’s success, enabling powerful optimizations and flexible toolchain development.
Over the years, LLVM IR has seen enhancements in its type system, allowing for a more accurate representation of high-level language constructs and more effective optimizations. The introduction of metadata in LLVM IR enabled the representation of additional information, such as source-level debug information, aliasing information, and optimization hints, further improving the compiler’s ability to generate efficient code while maintaining high-level semantic information.
The SSA form, a cornerstone of LLVM IR’s design, has been refined to improve memory efficiency and support more complex transformations. Innovations such as introducing the phi node allowed for more sophisticated data flow analysis and optimization techniques, contributing to LLVM IR’s ability to streamline compilation processes and enhance code performance.
As LLVM expanded to support a broader range of target architectures, LLVM IR evolved to include features enabling better cross-platform development and optimization. This IR included the introduction of abstract representations for hardware-specific features and the development of a more flexible and powerful instruction selection framework to generate optimized machine code for different processors.
The optimization capabilities of LLVM IR have been continuously expanded, with the addition of new passes and the refinement of existing ones to improve both compile-time efficiency and runtime performance. The modular architecture of LLVM has facilitated the integration of cutting-edge optimization techniques from academic research and industrial practice, making LLVM IR a living platform that evolves with the needs of its users.
Community contributions have played a crucial role in the evolution of LLVM IR. The open-source LLVM model has encouraged developers worldwide to contribute improvements, extensions, and new features to LLVM IR, driving its growth and adaptation. This collaborative development model has ensured that LLVM IR remains at the forefront of compiler technology, addressing the needs of a diverse user base.
Looking to the future, LLVM IR continues to evolve, with ongoing work to enhance its expressiveness, efficiency, and utility. Innovations in parallel computing, security, and machine learning are influencing the development of LLVM IR, ensuring it remains a vital tool for modern software development and compiler research. The evolution of LLVM IR is a continuous process shaped by the challenges and opportunities of computing’s ever-changing landscape.
LLVM IR Operations
LLVM IR operations form the backbone of its functionality, providing a rich set of instructions that enable the representation of complex program constructs in a form that is both understandable to humans and suitable for machine processing. These operations encompass various functionalities, from basic arithmetic operations to complex control flow and memory management mechanisms. The design of LLVM IR operations adheres to the principles of simplicity, efficiency, and flexibility, ensuring that LLVM IR remains powerful yet manageable.
Basic Operations
LLVM IR includes a comprehensive suite of basic operations that perform arithmetic, logical, and bitwise computations. These operations are strongly typed, requiring operands to be the same type and explicitly specify the result type. This strong typing facilitates type safety and enables more efficient code generation. Basic operations include addition, subtraction, multiplication, division, and comparisons, which are fundamental to any computation.
Control Flow Operations
Control flow operations in LLVM IR manage the execution flow of programs. The br (branch) instruction supports conditional and unconditional branching, enabling the construction of if-else structures and loops. The switch instruction facilitates multi-way branching, similar to switch-case statements in high-level languages. LLVM IR also introduces the phi node, a critical component of its SSA form, which selects values based on the predecessor of the current block, enabling complex flow control mechanisms like loops and conditional statements to be represented efficiently.
Memory Management Operations
Memory management is a crucial aspect of LLVM IR, with operations designed to handle allocation, deallocation, and memory access. The alloca instruction allocates memory on the stack, while load and store instructions read from and write to memory locations, respectively. These operations ensure precise control over memory, essential for generating efficient low-level code that adheres to the constraints and capabilities of the target architecture.
Function Operations
LLVM IR represents functions as first-class values, with operations to define, call, and manipulate functions. The call instruction invokes a function, while the ret instruction returns control from a function to its caller, optionally returning a value. Function attributes convey calling conventions or optimization opportunities, such as noreturn for functions that do not return to the caller.
Aggregate Operations
To handle complex data structures like arrays, structures, and vectors, LLVM IR provides aggregate operations. These include instructions for constructing aggregates, accessing elements or fields (extractvalue and insertvalue), and creating vectors (shufflevector). These operations allow LLVM IR to represent and manipulate high-level data structures efficiently.
Miscellaneous Operations
LLVM IR includes operations for exception handling, inline assembly, and metadata attachment. Exception handling operations (invoke, landingpad) facilitate trying-catch semantics implementation. Inline assembly allows embedding assembly code within LLVM IR, providing a mechanism for operations that require direct hardware manipulation. Metadata operations enable the association of additional information with instructions or functions without affecting their semantics and are helpful for optimization hints, debug information, and more.
LLVM IR’s comprehensive set of operations, combined with its design principles, provides a robust foundation for compiler optimization and code generation, enabling LLVM to serve as a versatile toolchain for a wide range of programming languages and target architectures.
Optimization Techniques and LLVM IR
Optimization techniques in LLVM IR play a crucial role in enhancing the performance and efficiency of compiled programs. LLVM employs many optimization passes, each designed to analyze and transform the IR code to improve its execution speed, reduce memory usage, and eliminate redundant computations. The following machine-independent and machine-dependent optimizations can occur at various stages of the compilation process.
Machine-Independent Optimizations
Constant Propagation and Folding: This technique evaluates expressions at compile time that involve constant values, replacing them with their computed results. Doing so reduces runtime computations and simplifies the IR.
Dead Code Elimination (DCE): Identifies and removes instructions that do not affect the program’s observable behavior, such as unused results of computations. This optimization reduces the size of the generated code and the execution time.
Loop Invariant Code Motion (LICM): Moves computations that produce the same result every iteration out of loops. Compute these values before the loop begins, and it reduces the number of instructions executed during each iteration.
Function Inlining: Expands the body of a called function inline at the call site. This inlining can reduce the function call overhead and enable further optimizations like constant folding within the inlined function body.
Global Value Numbering (GVN): Eliminates redundant computations by identifying instructions that compute the same value and replacing them with a single, shared computation. This optimization is effective at reducing both code size and execution time.
Machine-Dependent Optimizations
Instruction Selection: Transforms the high-level IR into a sequence of machine instructions specific to the target architecture. This process involves choosing the most efficient instructions to perform each operation.
Register Allocation: Assigns variables to machine registers, aiming to minimize the need for loading and storing variables in memory. Efficient register allocation is crucial for maximizing the use of fast processor registers and minimizing slow memory accesses.
Instruction Scheduling: Orders instructions to avoid pipeline stalls and take advantage of instruction-level parallelism available in modern CPUs. This optimization can significantly improve execution speed on architectures with deep pipelines or multiple execution units.
Peephole Optimizations: Performs local transformations on small sequences of machine instructions, such as replacing complex instruction sequences with simpler equivalents or optimizing conditional branches. These optimizations fine-tune the machine code for better performance and smaller size.
Framework for Optimization
LLVM provides a flexible framework for implementing these optimizations, consisting of a pass manager that orchestrates the execution of optimization passes and an extensive API for analyzing and transforming the IR. LLVM’s modular design allows developers to create custom optimization passes tailored to specific needs or target architectures.
Optimizations in LLVM IR are applied iteratively, allowing multiple passes to refine the code progressively. The optimization level (-O1, -O2, -O3, etc.) specified during compilation controls the aggressiveness of the optimization process, balancing compilation time against the performance of the generated code.
The design and implementation of optimization techniques in LLVM IR underscore the framework’s commitment to producing high-quality, efficient machine code suitable for a wide range of target architectures and application domains. Through continuous development and refinement of its optimization passes, LLVM remains at the forefront of compiler technology, enabling developers to achieve optimal performance from their software.
Applications of LLVM IR
LLVM IR finds applications across a broad computing spectrum, significantly impacting software development, compiler construction, and performance optimization. Its versatility and efficiency make it an invaluable tool in various domains, including but not limited to just-in-time (JIT) compilation, static analysis, domain-specific languages (DSLs), and hardware synthesis. The applications of LLVM IR demonstrate its flexibility and power, contributing to its widespread adoption and the advancement of compiler technology.
Just-In-Time (JIT) Compilation
LLVM IR is extensively used in JIT compilation scenarios, where it acts as an intermediate step between high-level language code and machine-specific binary code. Languages like Python, Ruby, and JavaScript benefit from LLVM-based JIT compilers, which compile code at runtime to improve execution speed compared to traditional interpreters. LLVM’s ability to generate optimized machine code dynamically for the executing platform allows programs to run faster, enhancing the performance of applications and enabling complex computations in real time.
Static Analysis Tools
The detailed and structured nature of LLVM IR makes it an excellent candidate for static code analysis. Tools built on LLVM can examine LLVM IR to detect potential bugs, security vulnerabilities, and performance issues without executing the program. This capability is invaluable for improving code quality, ensuring security compliance, and identifying optimization opportunities early in development.
Domain-Specific Languages (DSLs)
LLVM IR is a target for domain-specific language compilers, enabling developers to leverage LLVM’s optimization capabilities and target architecture support for specialized programming languages. DSLs in scientific computing, graphics rendering, and database querying can benefit from compiling to LLVM IR. It can then be optimized and translated to efficient machine code for various hardware platforms. This approach simplifies the development of high-performance DSL compilers by abstracting away the complexities of machine-specific code generation and optimization.
Hardware Synthesis and Simulation
In hardware design and simulation, LLVM IR represents and manipulates hardware description languages (HDLs). By targeting LLVM IR, developers can apply LLVM’s optimization passes to hardware designs, potentially reducing the complexity of the generated circuits. Furthermore, LLVM-based tools can simulate the execution of hardware designs described in LLVM IR, facilitating rapid prototyping and testing of digital circuits before physical implementation.
Cross-Platform Development
LLVM IR’s target-independent nature makes it an ideal tool for cross-platform software development. By compiling high-level code to LLVM IR, developers can generate optimized binaries for different hardware architectures and operating systems from the same source code. This capability significantly simplifies developing applications that run on various platforms, from desktops and servers to mobile devices and embedded systems.
Optimization of Machine Learning Models
LLVM IR is increasingly used to optimize machine learning models, particularly in compiling and optimizing models for inference on diverse hardware platforms. Frameworks that convert high-level descriptions of machine learning models into LLVM IR can leverage LLVM’s optimizations to generate efficient execution code, improving machine learning inference tasks’ performance and energy efficiency.
The applications of LLVM IR highlight its role as a cornerstone of modern compiler infrastructure, offering a robust, flexible, and efficient platform for software development and beyond. LLVM IR enables innovative solutions to complex problems across the spectrum of computing disciplines by providing a common framework for code representation, optimization, and translation.
LLVM IR and Cross-Platform Development
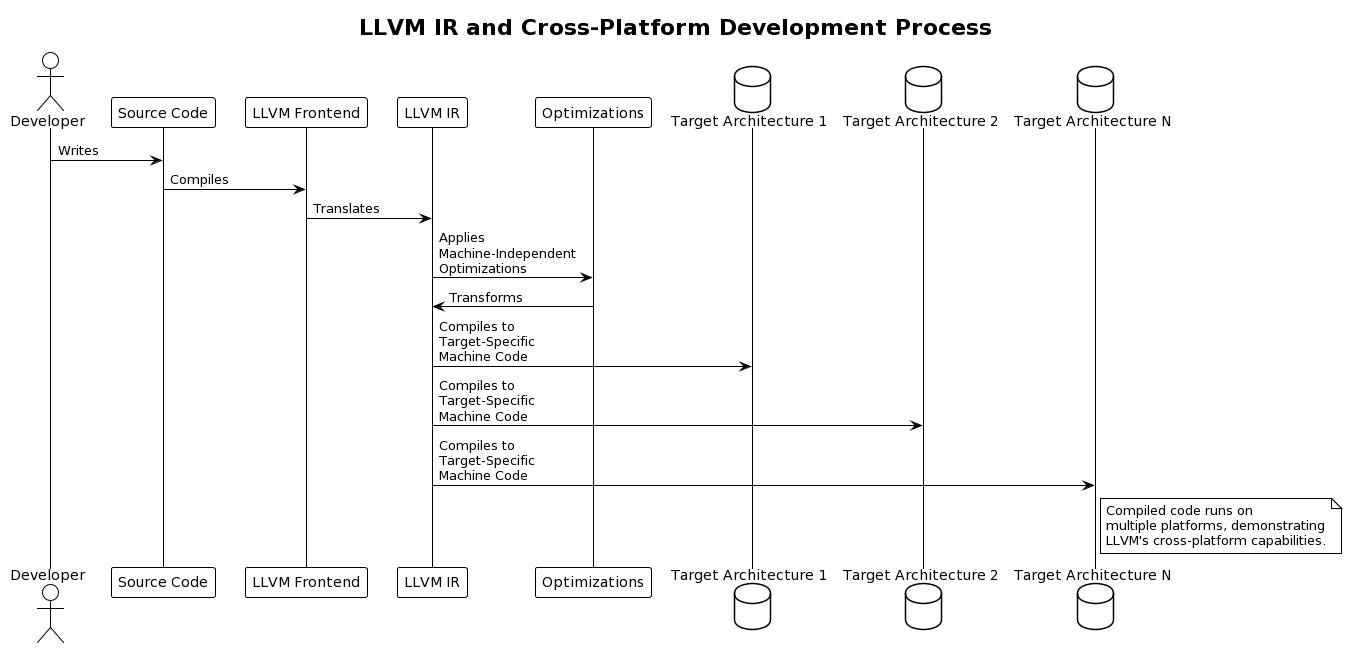
LLVM IR plays a pivotal role in cross-platform development by bridging high-level programming languages and a wide array of hardware architectures. This intermediary representation allows developers to write code once and compile it for various platforms, ranging from traditional CPUs to GPUs and other specialized hardware. The strength of LLVM IR in facilitating cross-platform development lies in its design principles, which emphasize target independence, modularity, and optimization.
Target Independence
LLVM IR is entirely independent of any hardware architecture, which is fundamental to its ability to support cross-platform development. This independence means that the IR captures the semantics of the source program without embedding assumptions about the specifics of any target architecture. As a result, the same piece of LLVM IR can be used as input to generate optimized machine code for different target architectures, including x86, ARM, MIPS, and more, by going through LLVM’s backend processes tailored for each target.
Modularity and Extensibility
The modular and extensible nature of LLVM’s architecture further supports cross-platform development. LLVM provides a comprehensive suite of tools and libraries to construct compilers, optimizers, and runtime environments for various programming languages. This modularity enables developers to easily extend LLVM to support new hardware platforms by adding or modifying backend components responsible for code generation and optimization. Consequently, as new architectures emerge, LLVM can adapt quickly to provide first-class support, ensuring application portability to the latest platforms with minimal effort.
Optimization for Multiple Targets
One of LLVM’s key features is its ability to perform machine-independent and machine-dependent optimizations. Machine-independent optimizations are applied to the IR without regard to the target architecture, focusing on improving the overall logic and efficiency of the code. Subsequently, machine-dependent optimizations tailor the IR to the specifics of the target architecture, ensuring that the generated machine code optimizes the hardware’s capabilities. This two-level optimization process is crucial for cross-platform development, as it ensures that applications run on multiple platforms and achieve high performance on each one.
Supporting Cross-Platform Libraries and Frameworks
LLVM IR facilitates the development of cross-platform libraries and frameworks by enabling consistent behavior and performance across different environments. Libraries compiled to LLVM IR can be distributed in this form and then compiled to native code on the end user’s platform, ensuring they are continually optimized for the target hardware. This approach simplifies the maintenance of libraries and frameworks used in cross-platform applications, as developers can focus on a single codebase rather than managing multiple platform-specific versions.
Challenges and Solutions
Cross-platform development with LLVM IR is challenging, particularly in handling platform-specific features and optimizations. However, LLVM addresses these challenges through its flexible infrastructure, which allows for customizing the compilation process with target-specific passes and using conditional compilation techniques within the IR. Moreover, LLVM’s active community and open-source model encourage sharing solutions and best practices for cross-platform development, continuously expanding LLVM’s capabilities in this domain.
In conclusion, LLVM IR significantly simplifies and enhances cross-platform development by providing a common, optimization-friendly representation of code abstracted from hardware specifics. Through its design for target independence, modular architecture, and robust optimization framework, LLVM enables developers to build applications that run efficiently across a wide range of computing environments, making it an invaluable tool in today’s diverse and evolving technological landscape.
Metrics and Performance Evaluation
Metrics and performance evaluation play a crucial role in assessing the effectiveness of LLVM IR optimizations and ensuring that the compiled programs meet the desired efficiency and speed criteria. Performance evaluation involves a systematic process using well-defined metrics to quantify the improvements in program execution facilitated by LLVM’s optimization passes. These metrics help understand the impact of individual optimizations and guide further enhancements to the LLVM compilation process.
Key Metrics for Performance Evaluation
Execution Time: Measures a program’s total execution time, including CPU and system time. Reduction in execution time is often the primary goal of optimizations, indicating faster program performance.
Memory Usage: Quantifies the memory a program consumes during execution. Optimizations aim to reduce memory usage, which is critical for resource-constrained environments and can also influence execution speed due to reduced paging and cache misses.
Instruction Count: Counts the number of machine instructions a program executes. A lower instruction count can indicate more efficient code, although the relationship with execution time can be complex due to varying instruction latencies.
Cache Misses: Monitors the number of cache misses experienced during program execution. Optimizations that improve data locality can reduce cache misses, leading to significant performance improvements, especially on architectures with deep memory hierarchies.
Branch Predictions: Measures the accuracy of branch predictions. Mispredicted branches can severely impact performance, and optimizations that enhance branch predictability can lead to faster execution.
Performance Evaluation Process
The performance evaluation process typically involves several steps, starting with selecting benchmarks or test cases representative of real-world usage scenarios. These benchmarks are executed before and after applying optimizations, and the metrics listed above are collected using performance analysis tools.
Baseline Measurement: Establishes performance metrics without any optimizations. This metric provides a reference point for assessing the impact of subsequent optimizations.
Incremental Optimization: Applies LLVM IR optimizations incrementally, measuring the impact of each optimization pass on the performance metrics. This step helps in identifying the most beneficial optimizations for a given codebase.
Comparative Analysis: Compares the optimized metrics against the baseline to quantify the improvements. This analysis may involve statistical methods to ensure that observed performance gains are significant and not due to experimental noise.
Profiling: Identifies hotspots or sections of code that consume the most resources. Profiling information can guide targeted optimizations to areas with the most significant impact.
Tools for Performance Evaluation
LLVM provides a suite of performance analysis and profiling tools, including llvm-mca for static performance analysis of machine instructions, perf for dynamic performance analysis on Linux systems, and Xcode Instruments for macOS. These tools, custom scripts, and third-party performance analysis software facilitate a comprehensive evaluation of optimization effectiveness.
Challenges and Considerations
Evaluating the performance of LLVM IR optimizations involves considering the trade-offs between different metrics (e.g., execution speed vs. memory usage) and the variability across other hardware platforms. Performance evaluation must also account for the impact of external factors such as operating system activity, hardware variability, and input data characteristics.
In summary, metrics and performance evaluation are essential for validating the effectiveness of LLVM IR optimizations, guiding the development of new optimizations, and ensuring that LLVM continues to meet the evolving performance requirements of diverse applications and platforms.
Future Directions for LLVM IR
The evolving landscape of computing technologies and the continuous quest for improved performance, portability, and efficiency in software development shape the future directions for LLVM IR. As LLVM IR stands at the core of the LLVM project, driving innovations in compiler design and optimization, several vital areas emerge as focal points for its future development.
Enhanced Support for Parallelism and Concurrency
With the increasing prevalence of multi-core processors and distributed computing architectures, enhancing LLVM IR to support parallelism and concurrency better is imperative. This support includes extending LLVM IR’s capabilities to represent parallel constructs explicitly, optimizing concurrent execution paths, and improving the analysis and transformation of code.
Improved Optimization Techniques
As hardware architectures become more complex, there is a continuous need for advanced optimization techniques that can understand and exploit specific architectural features. Future developments in LLVM IR will likely include more sophisticated analyses and transformations to optimize energy efficiency, reduce memory bandwidth consumption, and enhance execution speed on heterogeneous computing platforms.
Integration with Machine Learning
Integrating machine learning models into compiler optimization processes presents a promising avenue for future development. LLVM IR could serve as a platform for machine learning-based optimizations, where models predict the most effective optimization strategies for given code patterns or configurations, potentially surpassing the capabilities of traditional heuristic-based optimizations.
Better Support for Security
As software security becomes increasingly critical, LLVM IR must incorporate more features to enhance security. These features could involve built-in support for sanitization checks, more robust mechanisms for safe memory access, and the automatic hardening of code against common vulnerabilities. Enhancements in LLVM IR to support security features directly could significantly reduce the overhead of security checks and make secure coding practices more accessible to developers.
Cross-Platform and Cross-Language Interoperability
LLVM IR’s role as a bridge between high-level languages and target architectures positions it uniquely to further cross-platform and cross-language interoperability. Future enhancements may focus on standardizing and extending LLVM IR’s capabilities to represent high-level language features more directly, facilitating the seamless integration of code written in different languages and its deployment across diverse hardware platforms.
Support for Emerging Hardware
As new hardware architectures and computing paradigms emerge, LLVM IR must evolve to support these platforms effectively. This support includes adaptability to quantum computing, neuromorphic hardware, and specialized artificial intelligence and machine learning accelerators. Enhancing LLVM IR to model these new computing platforms’ unique features and constraints will be crucial for fully leveraging their capabilities.
Community and Ecosystem Growth
The future of LLVM IR also depends on the continued growth and diversification of its community and ecosystem. Encouraging contributions from various developers, researchers, and industry practitioners will drive innovation and ensure that LLVM IR remains at the forefront of compiler technology. Efforts to improve documentation, lower barriers to entry, and foster an inclusive community will be vital to sustaining LLVM IR’s development.
Conclusion
In conclusion, LLVM IR represents a cornerstone of modern compiler technology, encapsulating the principles of flexibility, efficiency, and extensibility within its design. The journey of LLVM IR from its inception to its current state illustrates a path of continuous innovation and adaptation, driven by the evolving demands of software development and the complexities of hardware architectures. Through its modular architecture and the adoption of the static single assignment (SSA) form, LLVM IR has established a solid foundation for compiler optimizations, enabling the generation of high-performance machine code across a wide range of computing platforms.
The evolution of LLVM IR, marked by significant milestones and enhancements, has been shaped by the contributions of a vibrant community of developers and researchers. This collaborative effort has not only expanded the capabilities of LLVM IR but also ensured its relevance and applicability to a broad spectrum of applications, from just-in-time (JIT) compilation and static analysis to the optimization of machine learning models and support for domain-specific languages (DSLs). The future directions of LLVM IR, encompassing enhanced support for parallelism, security, machine learning, and emerging hardware, promise to solidify its role as an indispensable tool in the compiler landscape further.
LLVM IR’s impact extends beyond the realm of compiler technology, influencing the development of more efficient, portable, and secure software. As computing continues to advance, the flexibility and adaptability of LLVM IR will remain pivotal in addressing the challenges and opportunities that lie ahead. In embracing future innovations and fostering an inclusive and diverse community, LLVM IR will continue to drive forward state-of-the-art compiler technology and software development.
LLVM IR is a testament to the power of open collaboration and the pursuit of excellence in software engineering. Its design, evolution, and wide-ranging applications underscore the critical role of compiler infrastructure in the modern computing era, enabling the development of applications that push the boundaries of what is possible. As LLVM IR continues to evolve, it will undoubtedly remain at the forefront of technological innovation, facilitating the creation of software that meets the ever-increasing demands of users and developers alike.
References
-
LLVM Official Documentation and Publications: The primary source of detailed and technical information about LLVM IR, its design principles, features, and optimization techniques. LLVM Project
-
Academic and Research Papers: Scholarly articles and conference papers that discuss the development, optimization techniques, and applications of LLVM IR in various computing domains.
- Chris Lattner and Vikram Adve, “LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation”, Proceedings of the International Symposium on Code Generation and Optimization: Feedback-directed and Runtime Optimization, 2004.
-
Community Contributions and Discussions: Insights and examples provided by the LLVM developer and user communities, including forums, mailing lists, and technical blogs.
- LLVM Developers’ Meeting talks and proceedings.
- LLVM Community forums and mailing lists.
-
Technical Blogs and Tutorials: Practical guides and discussions that illustrate using LLVM IR in real-world applications and software development projects.
- LLVM Blog: Insights into LLVM technology and developments.
-
Related Open Source Projects: Projects and tools built on or around the LLVM framework showcase the applications and impact of LLVM IR in diverse areas such as JIT compilation, static analysis, and domain-specific language support.