Developing PartiQL Postgres Extension
Abstract
This paper presents a new PostgreSQL extension, “pgpartiql,” that integrates PartiQL’s query execution into PostgreSQL, allowing it to process structured, semi-structured, and nested data. While adhering to SQL standards and enjoying widespread adoption, PostgreSQL has historically struggled with managing non-relational data types like nested and semi-structured data. PartiQL offers a solution by extending SQL capabilities to encompass non-relational data, yet PostgreSQL lacks native support.
The “pgpartiql” extension addresses this deficiency by expanding PostgreSQL’s capabilities to execute PartiQL queries, focusing on maintaining high performance. This extension aims to streamline data operations, enhance analytical flexibility, and preserve query efficiency, thereby broadening PostgreSQL’s scope in managing diverse data types and structures. “pgpartiql” provides users with a robust tool for advanced data management within the PostgreSQL framework.
Introduction
PostgreSQL, an open-source relational database system, stands out for its robustness and adherence to SQL standards. Despite its strengths, PostgreSQL cannot natively execute PartiQL queries, which extend SQL to manage structured, semi-structured, and nested data, thus limiting its flexibility in handling modern data types. To bridge this gap, this paper introduces a new PostgreSQL extension that facilitates the execution of PartiQL queries, thereby enhancing PostgreSQL’s capability to meet contemporary data management demands.
The extension prioritizes performance and scalability when processing PartiQL queries, aiming to streamline data integration, migration, and analysis processes. By incorporating PartiQL’s features into PostgreSQL, the project seeks to provide a comprehensive solution for complex data operations, leveraging PostgreSQL’s dependability alongside PartiQL’s versatile querying functionality.
Background Overview
PostgreSQL Extension Mechanism
PostgreSQL represents a sophisticated open-source object-relational database system known for its extensibility. This feature allows the integration of new functionalities, extending its native capabilities. PostgreSQL supports extensions and modules, introducing additional features like new data types, functions, operators, and indexing mechanisms. Such a framework ensures PostgreSQL’s versatility across diverse data management scenarios, meeting a broad spectrum of industry demands.
Overview of PartiQL
PartiQL enhances SQL by offering a unified query language for diverse data types, regardless of their structure or source. It builds on SQL’s relational algebra, including operations on traditional relational data and non-relational models, such as nested arrays and objects. Despite introducing new functionalities, PartiQL maintains SQL’s syntax, promoting user familiarity while addressing modern data management challenges.
PostgreSQL Data Handling Limitations
PostgreSQL is highly efficient with structured, relational data but encounters limitations with non-relational data types and intricate nested structures. Traditionally, addressing these challenges involves flattening nested data or crafting custom functions, which can be inefficient and complex. These issues become more pronounced with the growing prevalence of semi-structured and unstructured data in business environments. The need for frequent context switching and additional data processing steps complicates data handling, increasing the likelihood of errors and extending development timelines.
The integration of PartiQL through a new PostgreSQL extension will overcome these hurdles. By incorporating native support for PartiQL queries, PostgreSQL will enhance its data querying and manipulation flexibility. This move aims to minimize external data processing requirements and simplify working with non-relational data. Improving PostgreSQL with this extension leverages its existing strengths and aligns it with the dynamic demands of contemporary data management, ensuring its continued relevance and versatility in various applications.
Goals and Objectives
The primary goal of integrating PartiQL support into PostgreSQL through the “pgpartiql” extension is to enhance PostgreSQL’s data querying and manipulation capabilities, making it more versatile and efficient in handling both relational and non-relational data. This section outlines the specific objectives that the “pgpartiql” extension aims to achieve:
-
Unified Query Language: Integrate PartiQL into PostgreSQL as a unified query language, allowing the composition of a singular query for accessing both relational and non-relational data models. This integration simplifies managing various data types and structures, lowering the learning curve. Commercial or cloud-based databases built on PostgreSQL stand to gain from this streamlined approach. In a corporate environment, a PartiQL query, due to its semantic consistency, can be executed across multiple such databases with minimal to no changes. This capability contrasts sharply with the current situation, where each database variant, despite originating from PostgreSQL, exhibits divergences in data types, operations, and behaviors, such as differences in handling decimals, strings, timestamps, and null values.
-
Efficient Data Integration and Migration: Simplify the data integration and migration process by providing native support for querying nested and semi-structured data. The extension will eliminate the need for cumbersome data transformation or flattening processes, facilitating smoother data flows between different systems and formats.
-
Enhanced Analytical Capabilities: Improve PostgreSQL’s analytical capabilities by allowing direct queries on nested structures and arrays, thereby unlocking new insights from previously complex data to analyze directly in PostgreSQL. This objective aims to support more complex analytical queries and operations within the database.
-
Minimum latency: Ensure that the introduction of PartiQL queries does not add latency to PostgreSQL’s performance. The extension will focus minimizing overhead, and leveraging PostgreSQL’s existing performance features to handle PartiQL queries.
-
Seamless Integration: Design the “pgpartiql” extension to integrate seamlessly with PostgreSQL’s existing features and ecosystem. This extension includes compatibility with PostgreSQL’s security model, transaction management, and existing tooling, ensuring users can adopt PartiQL without significant changes to their current workflows.
-
Cross-Platform Compatibility: Facilitate broader adoption of PartiQL across different computing environments supported by PostgreSQL. This adoption includes ensuring that the extension works consistently across various operating systems and cloud platforms that deploy PostgreSQL.
-
Community and Ecosystem Support: Engage with the PostgreSQL community to gather feedback, encourage adoption, and provide support for the extension. The goal is to foster an ecosystem around “pgpartiql” where users can share use cases, optimizations, and best practices.
By accomplishing these objectives, the “pgpartiql” extension will significantly extend PostgreSQL’s capabilities, aligning it with the needs of modern, data-driven applications and making it a more powerful tool for developers and data analysts alike.
Design and Architecture
The “pgpartiql” extension will integrate PartiQL’s comprehensive querying capabilities with PostgreSQL. This integration facilitates a seamless experience for users working with complex data structures directly within their PostgreSQL databases. The architecture of “pgpartiql” is structured around several core components, each designed to translate and adapt PartiQL queries into a form that PostgreSQL can natively execute while maintaining high performance and compatibility with PostgreSQL’s existing functionalities.
Core Components
-
PartiQL Parser: A component that interprets PartiQL syntax, preparing it for translation into PostgreSQL’s SQL dialect.
-
Query Translator or Transpiler: Central to the extension, this translates PartiQL queries into equivalent PostgreSQL SQL queries.
-
Type System Mapper: Given the differences in data types between PartiQL and PostgreSQL, this mapper harmonizes types across the two languages, appropriately converting data types, especially during Data Definition Language (DDL) operations.
Design Principles
-
Minimum latency: Ensuring that the translation and execution of PartiQL queries do not adversely affect PostgreSQL’s performance. Strategies include leveraging existing PostgreSQL optimization mechanisms and introducing specific optimizations for handling PartiQL queries.
-
Seamless Integration: The extension will integrate smoothly with PostgreSQL, requiring minimal configuration changes and allowing users to employ PartiQL queries alongside traditional SQL queries without disruption.
-
Extensibility and Maintenance: Architecting “pgpartiql” with extensibility in mind, allowing for future enhancements to PartiQL support and easy updates to adapt to evolving PostgreSQL features.
Implementation
Developing a PostgreSQL extension like “pgpartiql” involves detailed steps, from writing the extension code to installing and using it within a PostgreSQL database. Below is a simplified step-by-step guide, including sample code snippets, to illustrate the development process. Please note, the following is a conceptual overview - a pseudocode, if you will; implementation details might vary based on the PartiQL’s Rust-based parser, PartiQL Scribe, and PostgreSQL versions.
The following diagram represents a candidate design to develop the extension:
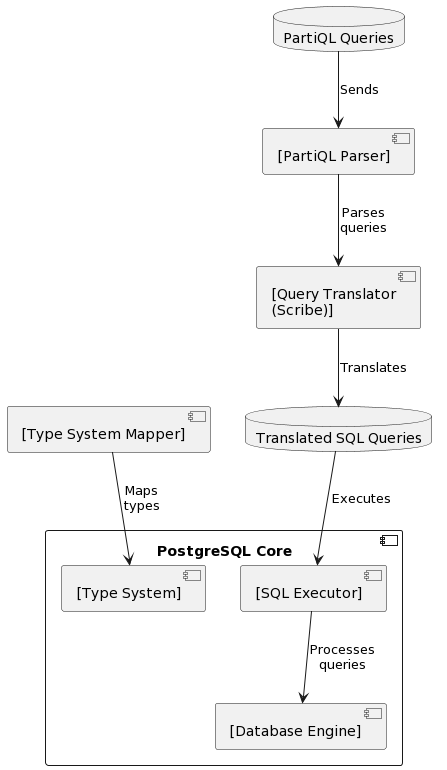
- The diagram starts with PartiQL Queries, representing the initial input from users.
- PartiQL Parser: This component parses PartiQL queries, preparing for translation.
- Query Translator (Scribe): It translates parsed PartiQL queries into SQL queries understandable by PostgreSQL.
- Translated SQL Queries: This database symbol represents the output of the translation process, now in PostgreSQL’s SQL format.
- Type System Mapper: It ensures that data types mapping in PartiQL queries to PostgreSQL’s data types.
- The PostgreSQL Core section outlines the internal components of executing the translated SQL queries, including the Database Engine for overall database operations, the SQL Executor for running SQL queries, and the Type System for managing data types.
Given the constraints and context provided earlier, direct implementation details, especially involving specific programming languages or technologies like C, Rust, or PartiQL integration specifics, are out of scope for this paper.
Step 1: Developing the Extension
A. Define the Extension’s SQL Wrapper
Create a SQL file (e.g., pgpartiql--1.0.sql) that PostgreSQL will use to load the extension. This file should define the wrapper functions that PostgreSQL will call to interact with the PartiQL parser and Scribe translator.
-- Define a function to execute PartiQL queries
CREATE OR REPLACE FUNCTION execute_partiql(query TEXT) RETURNS SETOF RECORD AS $$
BEGIN
-- Placeholder for calling the PartiQL parser and Scribe translator
-- Actual implementation will involve invoking external libraries or custom code
RETURN QUERY EXECUTE translate_and_execute(query);
END;
$$ LANGUAGE plpgsql;
B. Implementing Translation Logic
Assuming you have a C or Python module for interfacing with PartiQL’s parser and Scribe, you’ll need to write a function that PostgreSQL can call. Here’s a pseudo-implementation in C for a function that translates and executes a PartiQL query:
#include "postgres.h"
#include "fmgr.h"
#include "utils/builtins.h"
PG_MODULE_MAGIC;
PG_FUNCTION_INFO_V1(execute_partiql);
Datum
execute_partiql(PG_FUNCTION_ARGS)
{
char* partiql_query = TextDatumGetCString(PG_GETARG_DATUM(0));
// Placeholder for PartiQL query translation and execution
// This would involve calling the PartiQL parser and Scribe translator
// and then executing the resulting SQL query against PostgreSQL
PG_RETURN_TEXT_P(cstring_to_text("Result placeholder"));
}
Step 2: Packaging the Extension
Create a control file (pgpartiql.control) to define the extension metadata:
# pgpartiql.control
name = 'pgpartiql'
default_version = '1.0'
comment = 'Execute PartiQL queries in PostgreSQL'
Step 3: Installing the Extension
-
Compile Custom Code: If your extension includes custom C code, compile it into a shared library (
.sofile on Linux) and place it in PostgreSQL’s library directory. -
Deploy SQL and Control Files: Move your SQL file (
pgpartiql--1.0.sql) and control file (pgpartiql.control) to the PostgreSQL’s extension directory. -
Register the Extension: Log into your PostgreSQL database and run:
CREATE EXTENSION pgpartiql;
Step 4: Using the Extension
Once installed, you can use the execute_partiql function to run PartiQL queries directly within PostgreSQL:
SELECT * FROM execute_partiql('SELECT * FROM my_table WHERE id > 10');
Evaluation
After developing the “pgpartiql” extension, a comprehensive evaluation is essential to ensure its effectiveness, performance, and compatibility within the PostgreSQL ecosystem. This section outlines the methodologies and metrics for assessing the extension’s impact on PostgreSQL’s functionality and performance, especially when executing PartiQL queries.
Performance Benchmarks
- Query Execution Time: Compare the execution times of equivalent queries written in standard SQL and PartiQL (translated to SQL via “pgpartiql”) to assess any overhead the translation process introduces.
- Memory Usage: Measure the memory footprint of executing PartiQL queries through the extension versus native PostgreSQL queries to identify any significant resource consumption differences.
- Throughput: Evaluate the number of queries that can be processed per unit of time in a controlled environment to gauge any performance impact.
Compatibility and Integration Testing
- Feature Support: Verify that all PartiQL features supported by the extension correctly translate into PostgreSQL operations, including complex nested queries and data manipulation statements.
- Data Type Handling: Test the extension’s ability to handle a wide range of PartiQL and PostgreSQL data types, ensuring accurate mapping and conversion.
- System Integration: Ensure that “pgpartiql” seamlessly integrates with PostgreSQL’s existing functionalities, such as transaction management, security features, and extensions, without causing disruptions or conflicts.
Use Case Demonstrations
- Data Migration: Demonstrate the extension’s utility in simplifying data migration tasks between different AWS services and PostgreSQL, showcasing specific examples where PartiQL’s unified querying significantly reduces complexity.
- Analytical Workloads: Present case studies where the extension enhances PostgreSQL’s analytical capabilities, particularly in handling mixed data models, to derive insights from previously challenging datasets.
User Feedback and Community Engagement
- Early Adopters: Gather feedback from a select group of users who implement the extension in their projects, focusing on usability, performance, and any encountered issues.
- Open Source Community: Engage with the PostgreSQL and PartiQL open-source communities to solicit contributions, bug reports, and feature requests, fostering a collaborative development environment.
The evaluation phase is crucial for validating the “pgpartiql” extension’s effectiveness and ensuring it meets the needs of PostgreSQL users seeking to leverage PartiQL’s querying capabilities. The extension can be refined and optimized through rigorous testing and community engagement, contributing to PostgreSQL’s evolution as a versatile database system capable of handling today’s diverse data management challenges.
This structured approach to evaluation will not only underscore the technical feasibility and practical benefits of the “pgpartiql” extension but also highlight areas for further research and development, paving the way for broader adoption and continuous improvement.
Challenges and Limitations
Parsing Complexity
- Example: Complex nested queries in PartiQL may not have direct equivalents in PostgreSQL’s SQL dialect. For instance, a PartiQL query that seamlessly merges data from a JSON column with relational data could require convoluted SQL and additional JSON processing functions in PostgreSQL, potentially leading to inefficiencies.
Performance Overhead
- Example: The translation layer introduced by “pgpartiql” may add overhead to query execution times. A PartiQL query that performs aggregation over nested data might execute significantly faster in its native environment than its translated PostgreSQL counterpart, especially if the data size is substantial.
Data Type Mismatches
- Example: Mapping PartiQL’s rich data types to PostgreSQL might not always be straightforward. For example, PartiQL’s handling of missing or undefined data within nested structures may not align perfectly with PostgreSQL’s NULL semantics, leading to potential data integrity concerns.
Areas for Future Improvement
Enhanced Translation Efficiency
- Future Direction: Developing more sophisticated algorithms for query translation that can optimize PostgreSQL’s strengths. For instance, it leverages machine learning techniques to analyze query patterns and optimize translation paths based on historical performance data.
Advanced Type System Integration
- Future Direction: Extending PostgreSQL’s type system to mirror PartiQL’s more closely, potentially through custom data types or extensions. This mirroring could involve creating a PostgreSQL extension directly supporting PartiQL’s data types, reducing the need for complex mapping logic.
Performance Optimization
- Future Direction: Implementing specialized indexing strategies or custom execution plans for PartiQL queries. An example would be introducing a new index type in PostgreSQL designed explicitly for efficiently querying nested JSON data structures, mirroring PartiQL’s optimized access patterns.
Broader Language Support
- Future Direction: Expanding “pgpartiql” to support additional constructs from newer versions of PartiQL or other similar query languages that enhance working with semi-structured data. This support could involve community collaboration to update the “pgpartiql” extension as PartiQL evolves continuously.
While the “pgpartiql” extension offers significant benefits in bridging the gap between PostgreSQL and PartiQL, it also introduces challenges related to parsing complexity, performance overhead, and data type mismatches. Addressing these challenges requires ongoing development and innovation, focusing on enhanced translation efficiency, advanced type system integration, and performance optimization. Future improvements in these areas will mitigate current limitations and expand the extension’s capabilities, ensuring that PostgreSQL remains a powerful and flexible tool for managing and analyzing today’s complex data landscapes. Engaging with the community for feedback, contributions, and testing will drive these improvements forward, making “pgpartiql” an invaluable asset within the PostgreSQL ecosystem.
Conclusion
The development and integration of the “pgpartiql” extension into PostgreSQL represent a significant step towards enhancing the database’s capability to handle and query a blend of relational and non-relational data through PartiQL. This initiative addresses the growing need for databases to efficiently manage diverse data types and structures, reflecting the evolving data storage and analysis landscape. By enabling the execution of PartiQL queries within PostgreSQL, the extension simplifies interactions with complex data, making data operations more efficient and reducing the need for external data processing tools.
Despite challenges such as parsing complexity, performance overhead, and data type mismatches, the “pgpartiql” project highlights areas for future improvement. These include optimizing query translation, enhancing PostgreSQL’s type system to better align with PartiQL, and implementing performance optimizations tailored to PartiQL queries. The continuous development in these areas will address current limitations and broaden the extension’s utility, solidifying PostgreSQL’s position as a versatile and powerful tool for modern data management tasks.
The initiative to integrate PartiQL into PostgreSQL through “pgpartiql” promises to significantly reduce the barrier to working with semi-structured and nested data, offering users a unified query language across different data paradigms. As this project evolves, it is expected to foster a closer collaboration between database engineers, application developers, and data scientists, encouraging the adoption of PostgreSQL for a broader range of applications and use cases.
In conclusion, “pgpartiql” is poised to revolutionize how users interact with PostgreSQL by providing enhanced data querying and analysis flexibility. Its development underscores the importance of adapting traditional relational databases to meet the demands of handling semi-structured data, ensuring that PostgreSQL continues to serve as a cornerstone in the data management ecosystem. Future enhancements and community involvement will be vital in realizing the full potential of this extension, driving forward the capabilities of PostgreSQL in the era of complex data landscapes.